Chapter 4 Panel Data
4.1 Unemployment
Unemployment occurs when someone is willing and able to work but does not have a paid job. Unemployment is measured by the unemployment rate. The unemployment rate is the most commonly used indicator for understanding conditions in the labour market.
The personal and social costs of unemployment include severe financial hardship and poverty, debt, homelessness and housing stress, family tensions and breakdown, boredom, alienation, shame and stigma, increased social isolation, crime, erosion of confidence and self-esteem, the atrophying of work skills and ill-health.
4.1.1 On decline in Germany
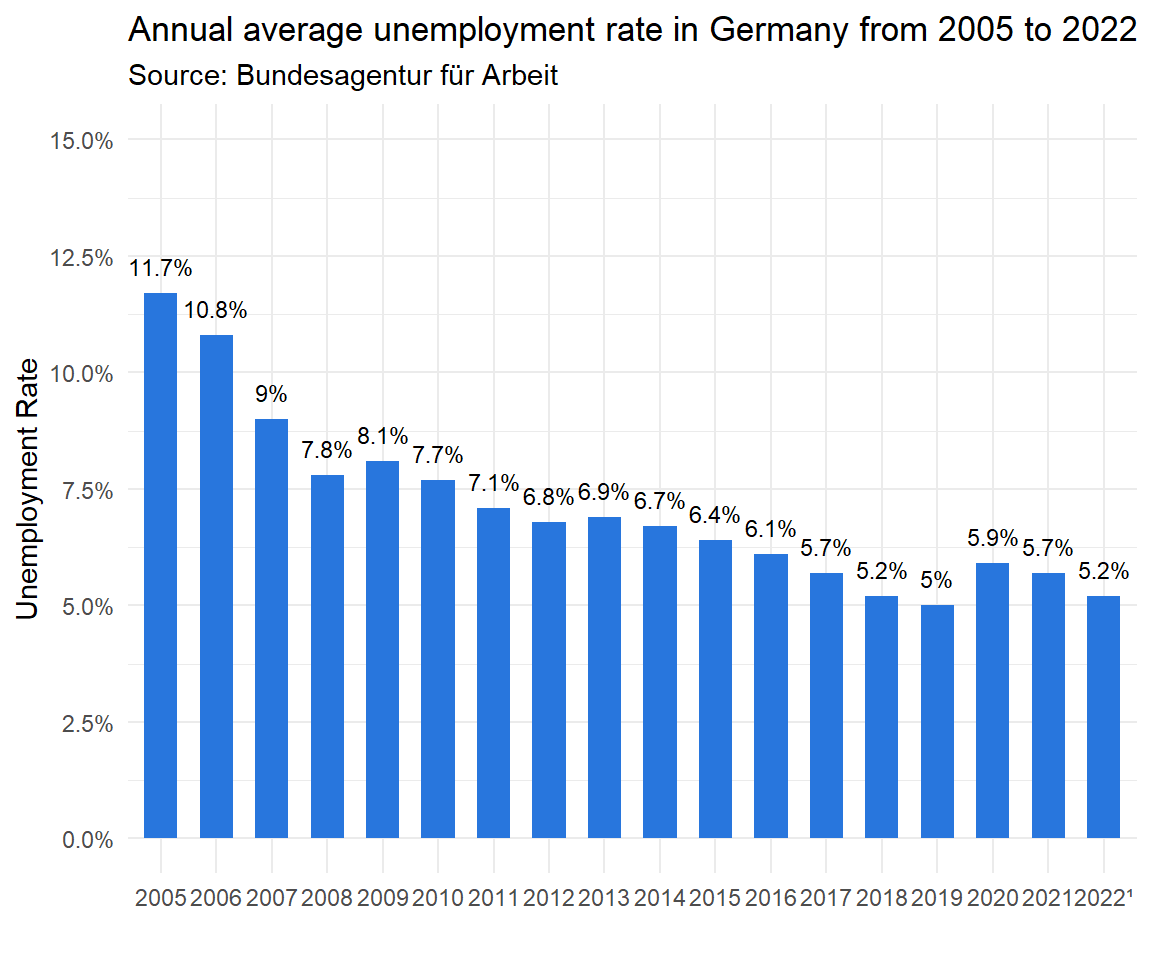
Figure 4.1: Unemployment rate in Germany
Reading
How Low Can Unemployment Really Go? Economists Have No Idea "Here are two things most economists can agree upon: They want an economy where everyone who seeks a job can get one. Yet for the economy to be dynamic, some people will always be unemployed, at least temporarily as they move between jobs."
Life after college.

Panel data allows to analyze the level of unemployment in Germany as well as the changes and trajectories of individuals. We can separate a frictional unemployment component and a permanent unemployment share. Frictional unemployment is a form of unemployment reflecting the gap between someone voluntarily leaving a job and finding another. As such, it is sometimes called search unemployment. Is search unemployment acceptable? Is it different from long-term unemployment? What do you think.
4.1.2 Measurement
The unemployment rate represents the proportion of the civilian labour force that is unemployed. Consequently, measuring the unemployment rate requires identifying who is in the labour force. The labour force consists of all employed and unemployed persons of working age. What exactly is defined as employment? Employment status can be defined via a threshold of working hours or income. Who is in the working age?
Reading
In Australia, the Australian Bureau of Statistics (ABS) conducts a survey each month – called the Labour Force Survey – in which it asks around 50,000 people. As part of this survey, the ABS groups people aged 15 years and over (the working-age population) into three broad categories:
- Employed – includes people who are in a paid job for one hour or more in a week.
- Unemployed – people who are not in a paid job, but who are actively looking for work.
- Not in the labour force – people not in a paid job, and who are not looking for work.
Read More: Unemployment: Its Measurement and Types
4.2 Application
4.2.1 Data Inspection
SOEP practice data (2015 - 2019) comes labeled and ready for analysis. SOEP provides a digital object identifier (DOI) for this data: https://doi.org/10.5684/soep.practice.v36.10
library(haven)
soep <- read_dta("https://github.com/MarcoKuehne/marcokuehne.github.io/blob/main/data/SOEP/practice_en/practice_dataset_eng.dta?raw=true")This practice data contains socio-economic information on children, education, job, health, satisfaction and income. It contains 15 variables and 23522 observations.
| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| syear | 5 | 0 | 2016.8 | 1.4 | 2015.0 | 2017.0 | 2019.0 | 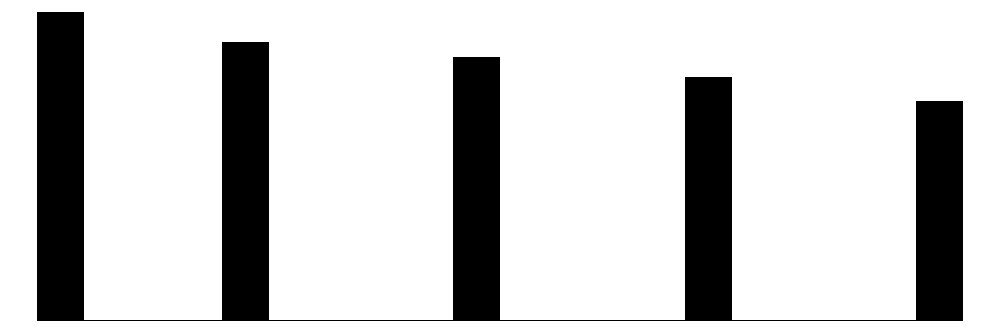 |
| sex | 2 | 0 | 0.5 | 0.5 | 0.0 | 1.0 | 1.0 |  |
| alter | 86 | 0 | 48.3 | 18.3 | 17.0 | 48.0 | 102.0 | 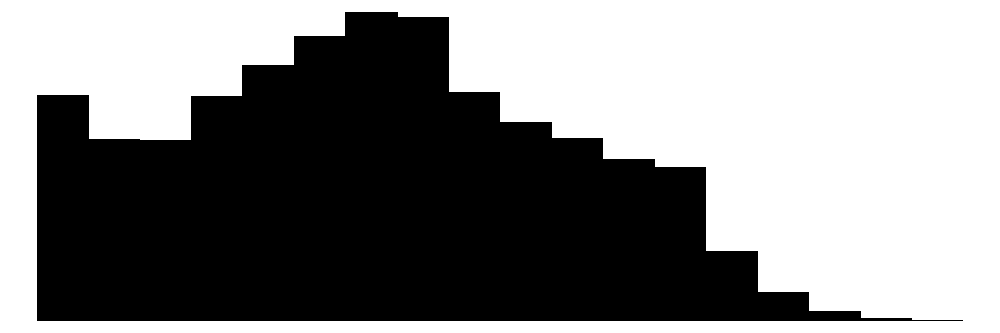 |
| anz_pers | 13 | 0 | 2.9 | 1.5 | 1.0 | 2.0 | 13.0 | 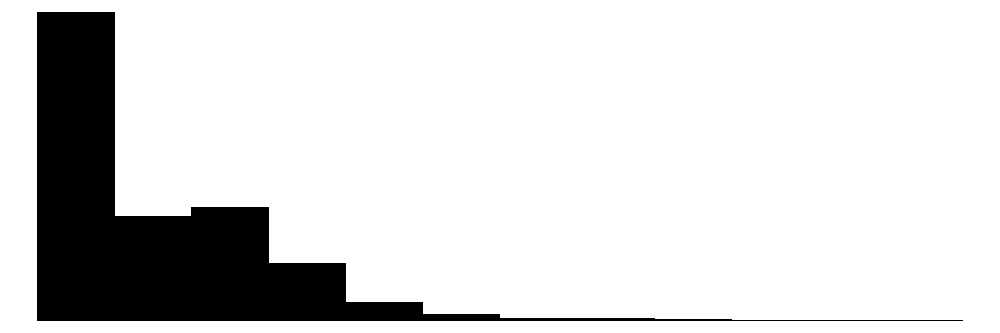 |
| anz_kind | 12 | 0 | 0.7 | 1.1 | 0.0 | 0.0 | 10.0 | 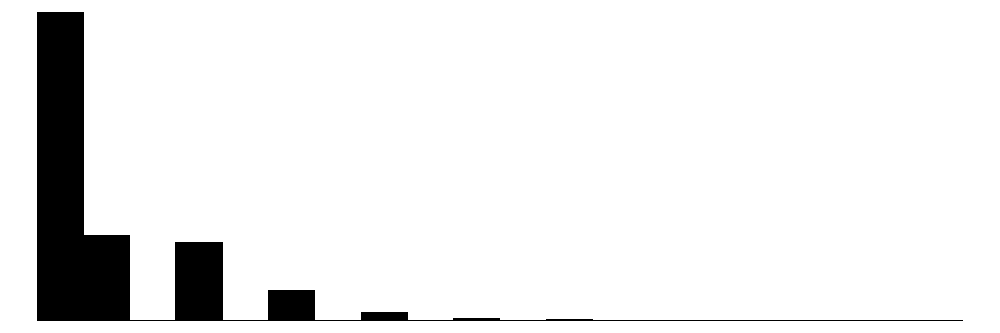 |
| bildung | 17 | 7 | 12.4 | 2.8 | 7.0 | 11.5 | 18.0 | 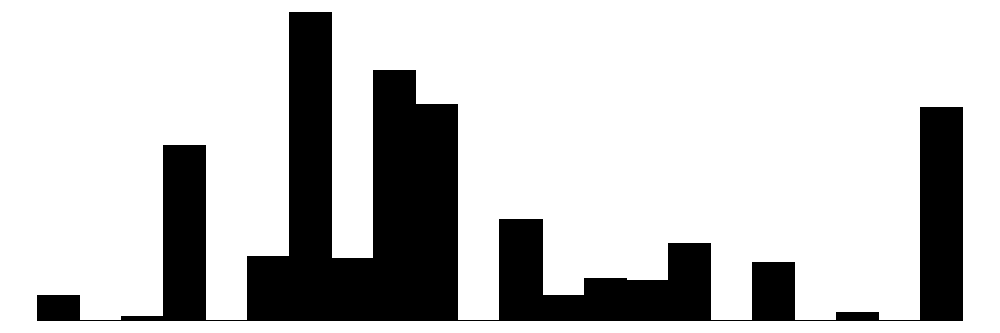 |
| erwerb | 7 | 0 | 3.0 | 1.8 | 1.0 | 2.0 | 6.0 | 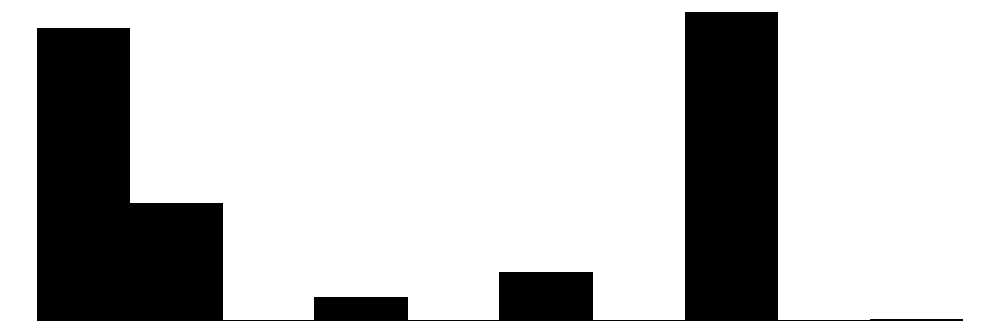 |
| branche | 84 | 42 | 60.5 | 25.3 | 1.0 | 64.0 | 99.0 | 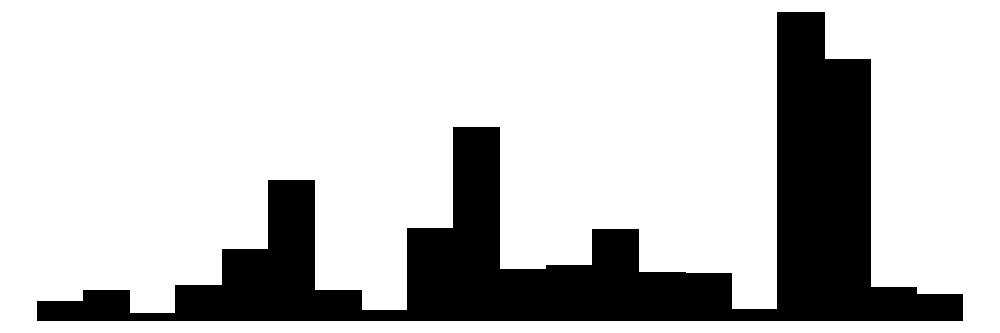 |
| gesund_org | 6 | 0 | 2.6 | 1.0 | 1.0 | 2.0 | 5.0 |  |
| lebensz_org | 12 | 3 | 7.4 | 1.7 | 0.0 | 8.0 | 10.0 |  |
| einkommenj1 | 13346 | 0 | 16775.8 | 22707.6 | 0.0 | 5786.1 | 269424.9 |  |
| einkommenj2 | 1871 | 0 | 315.7 | 1887.6 | 0.0 | 0.0 | 79179.9 |  |
| einkommenm1 | 14067 | 0 | 1645.6 | 2220.6 | 0.0 | 852.9 | 35260.9 |  |
| einkommenm2 | 607 | 0 | 11.0 | 134.0 | 0.0 | 0.0 | 12033.2 |  |
Column names are German, but attribute labels are in English. einkommenj1 contains Gross Income from Main Job/Year.
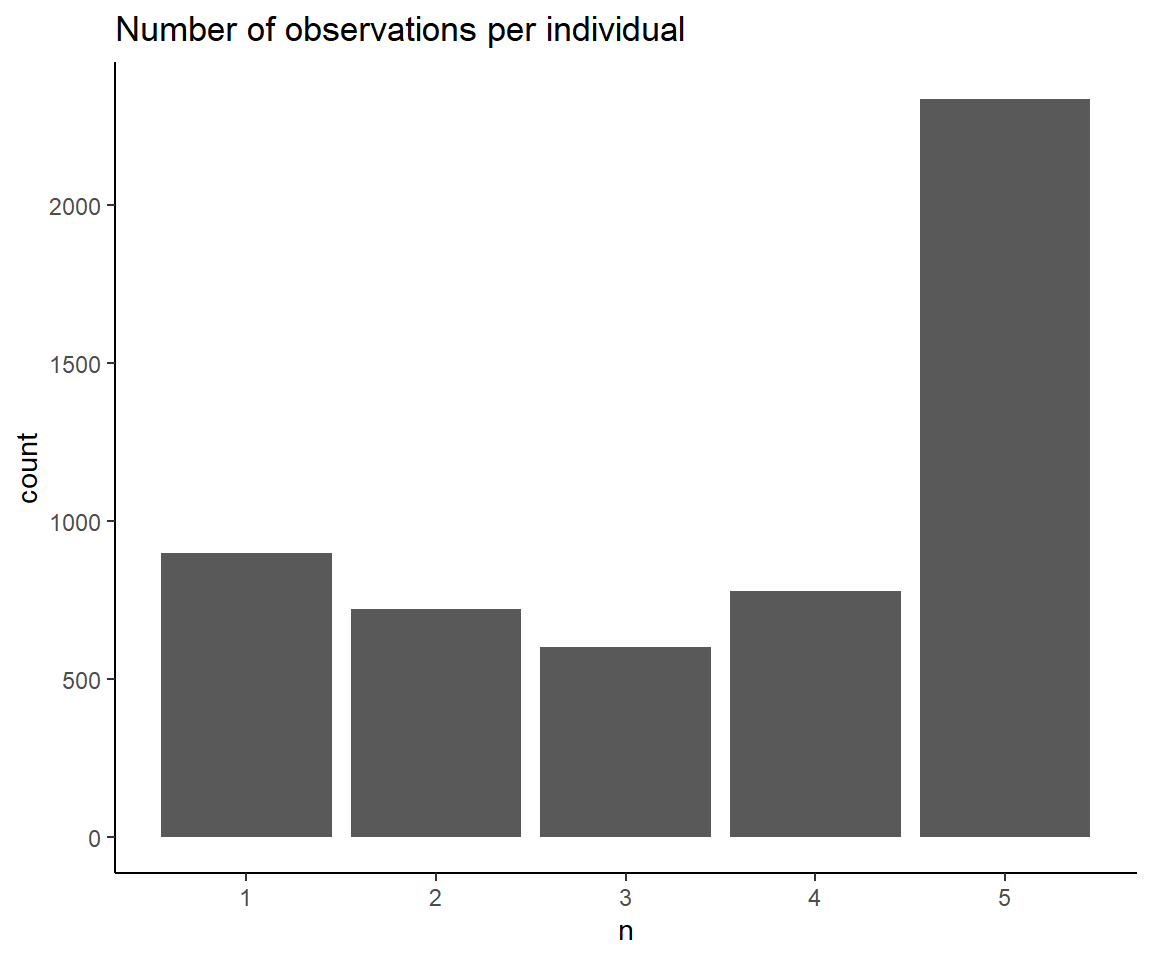
The documentation (click the DOI https://doi.org/10.5684/soep.practice.v36) tells that there are 6.355 people in the data. Every individual is likely observed multiple times (i.e. panel data). Pipe soep into count() of personal id. The tibble output already contains the number of rows. To literally access the value, ask nrow().
Adding arrange() means sorting the data by a variable (i.e. the temporarily created variable n) either ascending or descending (from high to low). Ascending is the default. For descending order apply the desc() command. group_by() is a powerful command, especially when working with panel data. It can do any form of data manipulation or analysis with respect to the chosen variable. At this stage it's a mere alternative count().
# soep %>% group_by(id) %>% count() %>% arrange(n) # try this alternative
soep %>% count(id) %>% arrange(n)
soep %>% count(id) %>% arrange(desc(n)) See result.
#> # A tibble: 6,355 × 2
#> id n
#> <dbl> <int>
#> 1 96 1
#> 2 137 1
#> 3 147 1
#> 4 183 1
#> 5 189 1
#> 6 229 1
#> 7 368 1
#> 8 371 1
#> 9 384 1
#> 10 443 1
#> # ℹ 6,345 more rowsRemember that the observation period is between 2015 and 2019, i.e. the minimum number of observations per individual is 1 year, the maximum is 5 years. Over the years, observations get less and less (panel attrition).
How many people are observed in all years? Filter for a specific n and ask for the number of rows or observations (alternatively you can check the tibble size again).
erwerb is the employment status in SOEP. Its labels range from -7 to 6. Use the attributes() command on a specific variable. It returns a set of information (object class is list). We can access elements of this list by the $ operator. Did you notice the small mistake in the labels? (Remember this is practice data.)
See result.
#> [-7] Only available in less restricted edition
#> -7
#> [-6] Version of questionnaire with modified filtering
#> -6
#> [-5] Not included in this version of the questionnaire
#> -5
#> [-4] Inadmissable multiple response
#> -4
#> [-3] not valid
#> -3
#> [-2] does not apply
#> -2
#> [-1] no answer
#> -1
#> [-1] Employed full-time
#> 1
#> [-2] Employed part-time
#> 2
#> [3] Training, apprenticeship
#> 3
#> [4] Irregular employment or in marginal
#> 4
#> [5] Not employed
#> 5
#> [6] Garage for disabled people
#> 6# A tibble: 3,550 x 2, i.e. there are 3550 ID-groups (or units or people).
Negative values indicate several different forms of missing data in SOEP.11 Actually, there are no negative values in this dataset. As for levels of a factor variables, labels can be empty.
4.2.2 Data Preparation
We summarize categories with a combination of mutate() and case_when(). For each value in erwerb conduct a logical comparison via == and assign a new value. In this case it combines Employed part-time with Irregular employment or in marginal.
soep <- soep %>%
mutate(erwerb = case_when(erwerb == 1 ~ "fulltime",
erwerb == 2 ~ "parttime",
erwerb == 3 ~ "parttime",
erwerb == 4 ~ "parttime",
erwerb == 5 ~ "unemployed",
erwerb == 6 ~ "parttime",
TRUE ~ "NA"))The unemployment rate represents the proportion of the civilian labour force that is unemployed. The labour force consists of all employed and unemployed persons of working age. Filter for working age between 18 and 67 years. There are 472 observations younger than 18 and 4125 older than 67.
The moment of glory has come for group_by(). It accepts multiple inputs. The following combination returns for each year and each employment status the number of observations with help of summarise() and n().
See result.
From this table, the unemployment rate for 2015 can be calculated manually:
\[\frac{1268}{2013+1261+1268} = 0.279172 = 27.92 \%\]
Having done this, step back to focus on years again and use different n-values per year to figure out the unemployment. Relate unemployed to those working either fulltime or partime.
See result.
The unemployment rate in this data is unreasonably high.
4.2.3 Data Visualization
4.2.3.1 Unemployment status
Pick up the calculation of the unemployment rate and pipe it into a ggplot() call. Define the axes elements within aes() (for aesthetics) and ask for points that are connected by a line.
soep %>%
group_by(syear, erwerb) %>%
summarise(n = n()) %>%
group_by(syear) %>%
mutate(unemployment_rate = n[3]/(n[1]+n[2]+n[3])) %>%
ggplot(aes(x = syear, y = unemployment_rate)) + geom_point() + geom_line() +
labs(x="Year", y="Unemployment Rate",
title = "Unemployment Rate in Germany between 2015 and 2019",
subtitle = "SOEP practice data")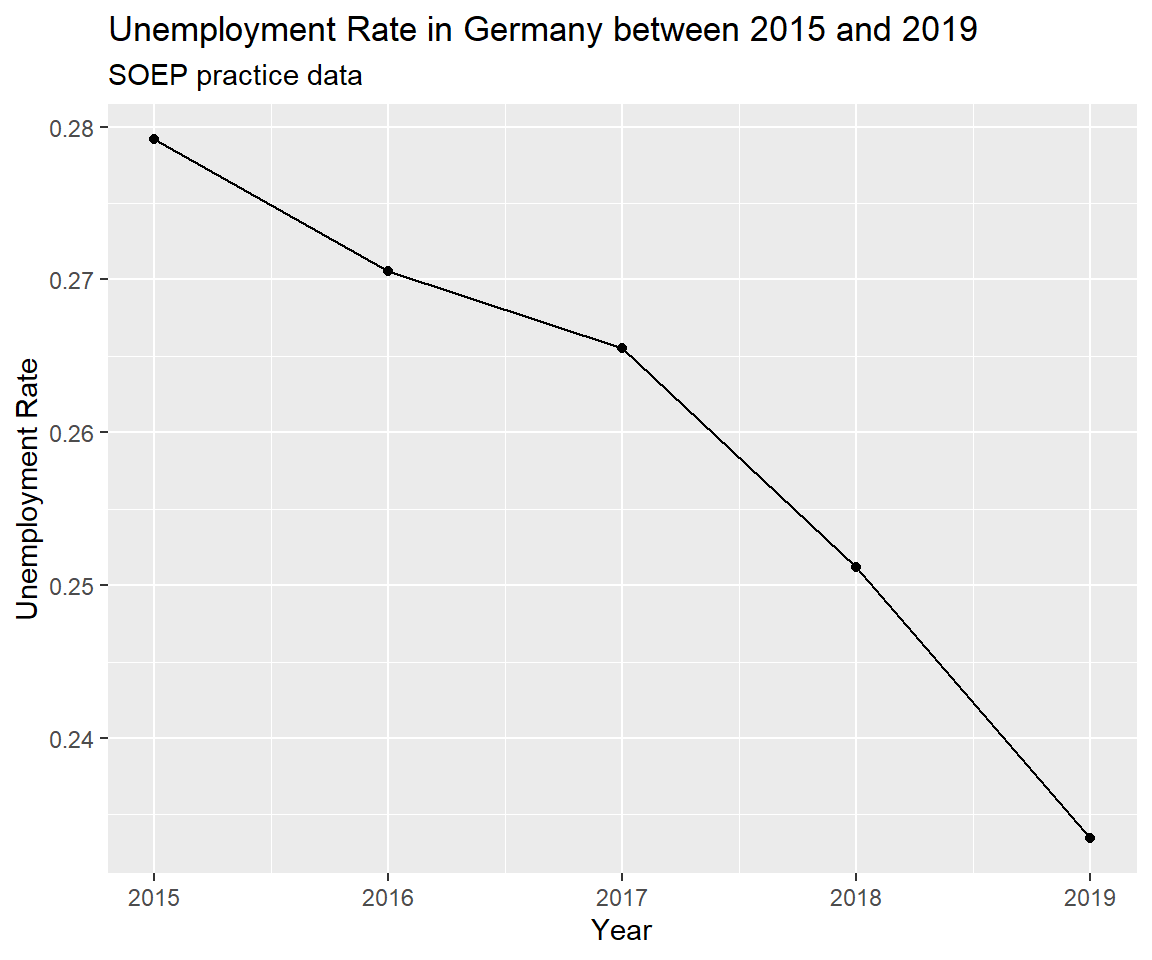
4.3 Panel Studies
Famous household panel data studies include:
- United States: Panel Study of Income Dynamics (PSID) since 1968
- Germany: Socio-Economic Panel (SOEP) since 1984
- United Kingdom: British Household Panel Survey (BHPS) since 1991
- Australia: Household, Income and Labour Dynamics in Australia Survey (HILDA) since 2001
These scientific datasets can often be analyzed for research and student theses free of charge.
Why are DOIs important? A DOI is a unique identifier for a digital document. DOIs are important in academic citation because they are more permanent than URLs, ensuring that your reader can reliably locate the source. Read More: What is a DOI? | Finding and Using Digital Object Identifiers↩︎
Read more on the SOEPcompanion Missing Conventions↩︎