Chapter 11 Linear Regression
11.1 What You Deserve Is What You Get
Do you believe that people get what they deserve? The statement "what you deserve is what you get" is a controversial one. It can be interpreted such that individuals are entirely responsible for their own outcomes and that they receive exactly what they deserve based on their efforts, abilities, and choices. This view assumes a meritocratic (performance-oriented) system where everyone has an equal opportunity to succeed based on their merit, and rewards are distributed accordingly.
We investigate annual income and how it is determined. The famous Mincer Equation is single-equation model that explains wage income as a function of schooling and experience. The equation suggests that higher levels of education and experience are positively associated with earnings, and the coefficients can be estimated using statistical methods to quantify the magnitude of these relationships. When everybody has access to schooling and the equal opportunities on the labor market, better school outcomes and work experience may be determined by people efforts, abilities, and choices.
11.2 Data & Sample
We use SOEP practice data to analyse yearly income. The analysis is restricted to people who are fulltime employed (Emp == 1) in the working age (Age <= 65) who report an annual income from main job of more than one Euro (Income > 1). We analyse the most recent cross-section of the data (syear == 2019). We drop a few cases with missing information, thus conduct a complete case analysis.
library(haven)
master <- read_dta("https://github.com/MarcoKuehne/marcokuehne.github.io/blob/main/data/SOEP/practice_en/practice_dataset_eng.dta?raw=true")
# The data comes with Stata labels that do not work with all tidyverse commands
library(sjlabelled)
soep <- remove_all_labels(master)
# Rename German to English variable names
library(tidyverse)
soep <- soep %>%
rename("Age" = "alter",
"Income" = "einkommenj1",
"NACE2" = "branche",
"Persons in HH" = "anz_pers",
"Kids" = "anz_kind",
"Education" = "bildung",
"Health" = "gesund_org",
"Satisfaction" = "lebensz_org",
"Emp" = "erwerb")
# Explicitly define the gender variable as a factor
soep <- soep %>% mutate(Female = factor(sex))
# Round annual income to two digits
soep <- soep %>% mutate(Income = round(Income, 2))
# Build the estimation sample based on the topic
soep <- soep %>%
filter(Emp == 1) %>%
filter(Age <= 65) %>%
filter(Income > 1) %>%
filter(syear == 2019)
# Conduct a complete case analysis
soep <- soep %>% filter(complete.cases(.))The estimation sample looks like this:
The descriptive statistics of the sample look like this:
| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| sex | 2 | 0 | 0.4 | 0.5 | 0.0 | 0.0 | 1.0 |  |
| Age | 47 | 0 | 45.4 | 11.2 | 18.0 | 47.0 | 65.0 | 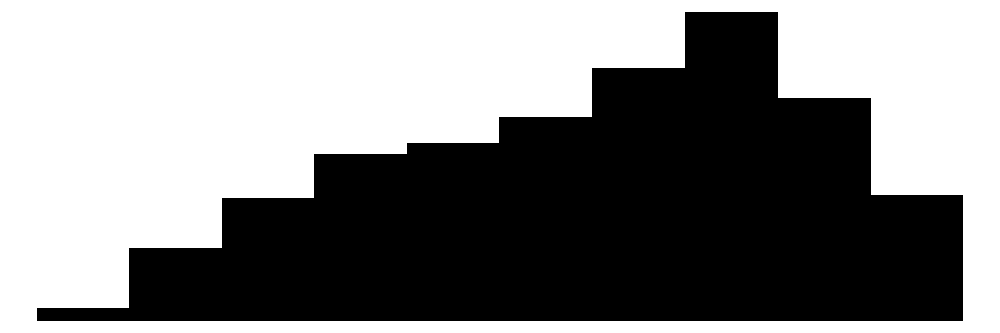 |
| Persons in HH | 10 | 0 | 2.9 | 1.4 | 1.0 | 3.0 | 10.0 | 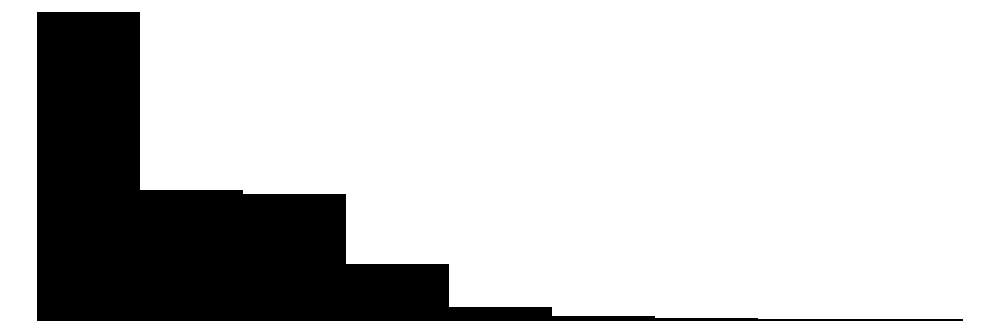 |
| Kids | 8 | 0 | 0.7 | 1.1 | 0.0 | 0.0 | 8.0 | 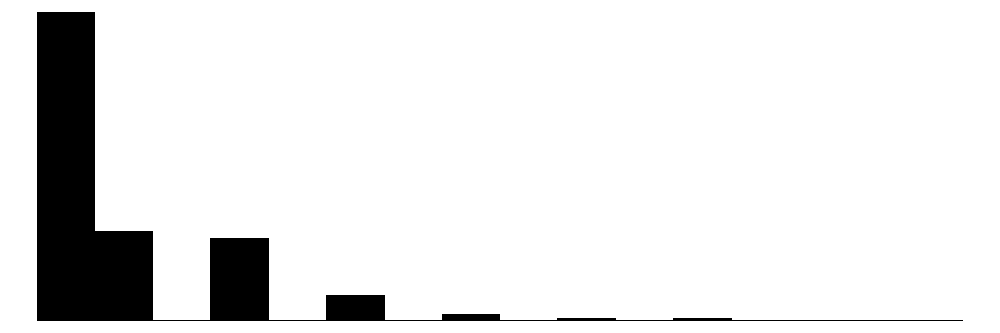 |
| Education | 16 | 0 | 12.9 | 2.8 | 7.0 | 12.0 | 18.0 | 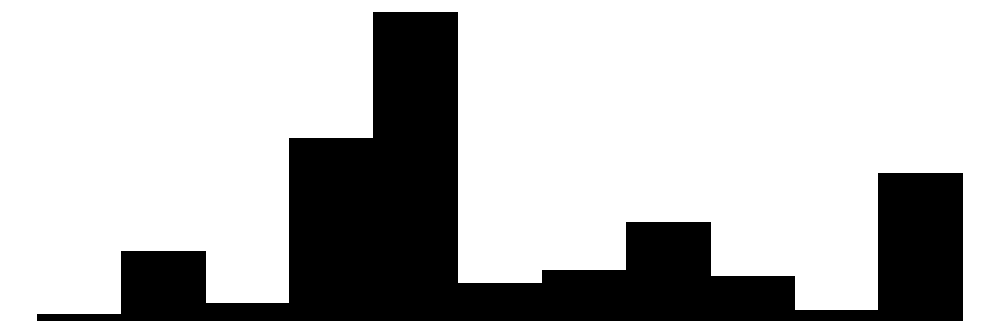 |
| NACE2 | 77 | 0 | 57.0 | 25.9 | 1.0 | 56.0 | 97.0 | 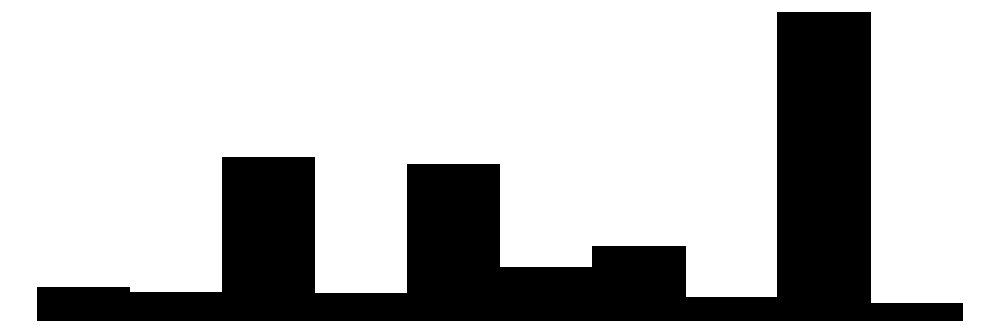 |
| Health | 5 | 0 | 2.4 | 0.9 | 1.0 | 2.0 | 5.0 | 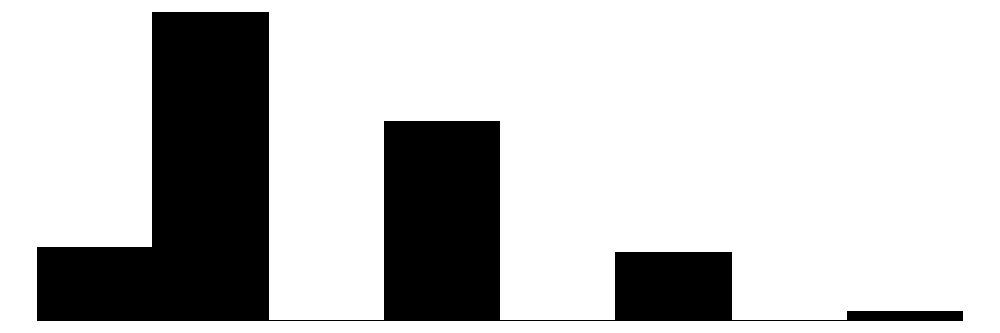 |
| Satisfaction | 11 | 0 | 7.6 | 1.4 | 0.0 | 8.0 | 10.0 | 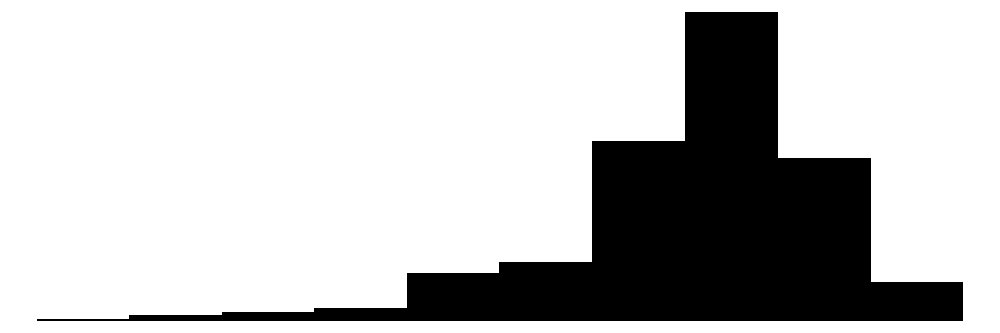 |
| Income | 1211 | 0 | 42145.2 | 23488.8 | 915.5 | 37337.3 | 257886.2 | 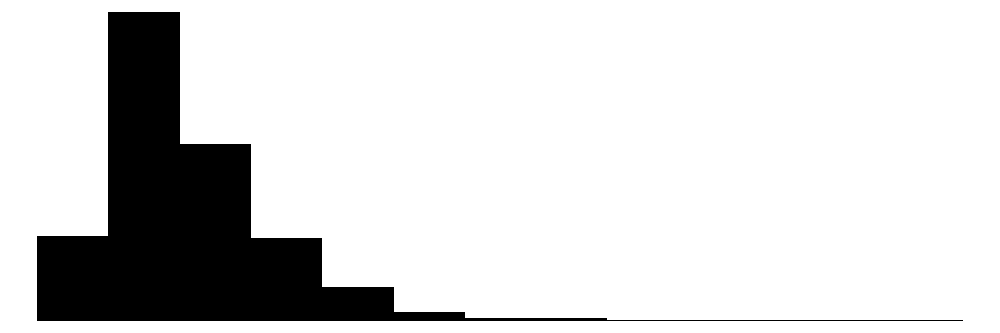 |
| Female | N | % | ||||||
| 0 | 779 | 64.3 | ||||||
| 1 | 432 | 35.7 |
The data is clean and ready for analysis. There are no missings. The working age ranges from 18 to 65 years. People have between 0 and 8 children. There are NACE codes for the job industry ranging from 1 to 97 in the data (theoretically from 1 to 99). But not all jobs are represented in the data (77 unique values). Health status is measured on a scale from 1 to 5 whereas life satisfaction is measured on a scale between 0 and 10. The minimum annual income is about 915 Euro. We could have restricted the income variable to the minimum wage in Germany. Assume it is 12€/h and people in full-time work 8h/day. Starting from 365 days a year, there are 104 weekends, assume there are 11 public holidays and 30 days of vacation. 220 working days remain earning a minimum yearly income of about 220*8*12 = 21120 Euro. In the data, 165 people report earning less than that.
11.3 Data Visualization
We create a scatterplot of income (on the y-axis) versus age (on the x-axis). Data points are colored by gender (blue for men, red for women). A linear regression line is added per gende.r
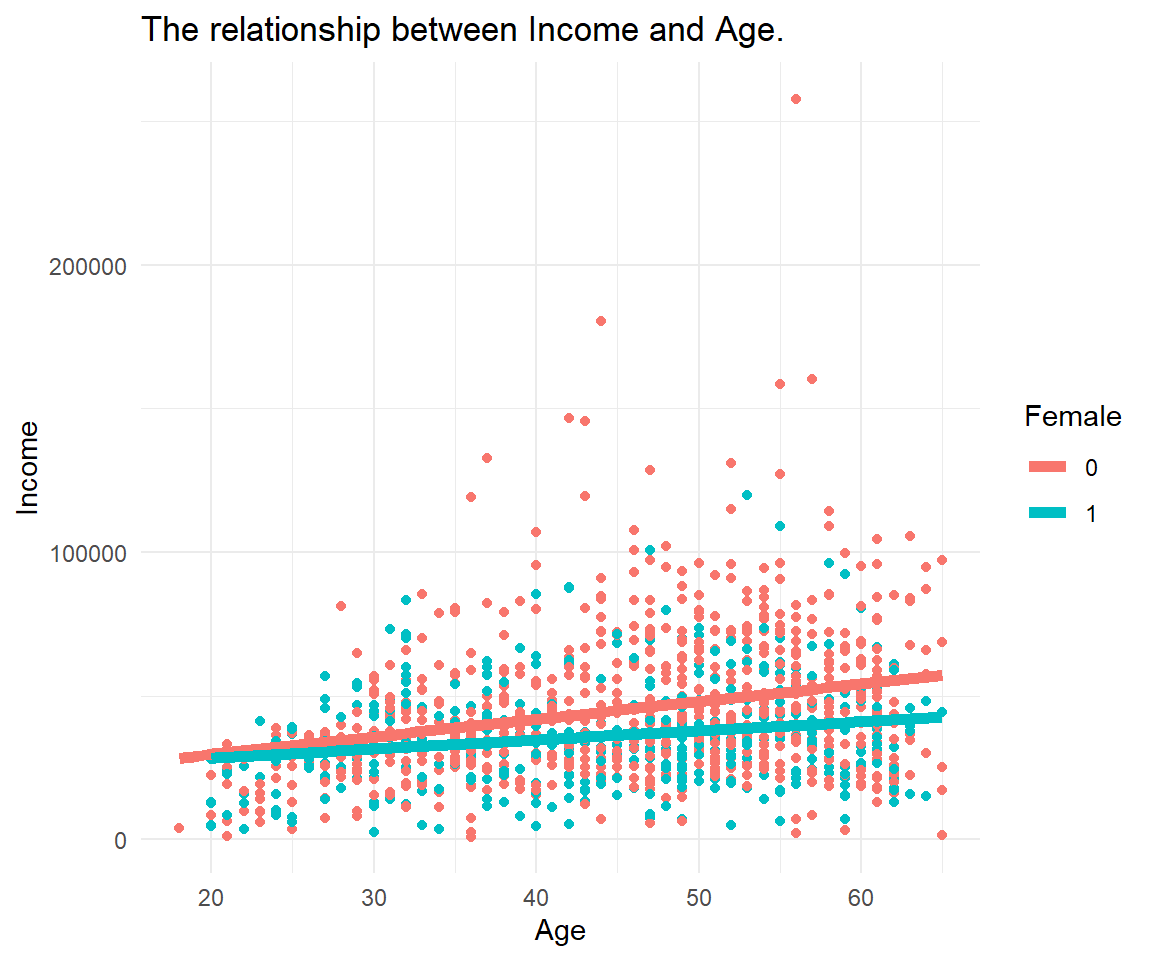
11.4 Simplest Regression
The simplest regression or empty model does not contain any explanatory variable.
simplest <- lm(Income ~ 1, data=soep)
library(modelsummary)
modelsummary(title = 'Empty Model.',
list("Income" = simplest),
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.',
coef_map = cm)| Income | |
|---|---|
| Constant | 42145.215 |
| (674.976) | |
| Num.Obs. | 1211 |
The graphs below illustrate the empty model that estimates an average annual income. The left panel shows the mean income for the entire sample (sometimes referred to as grand mean), the right panel shows the data colored by gender (it can be considered two overlie plots).
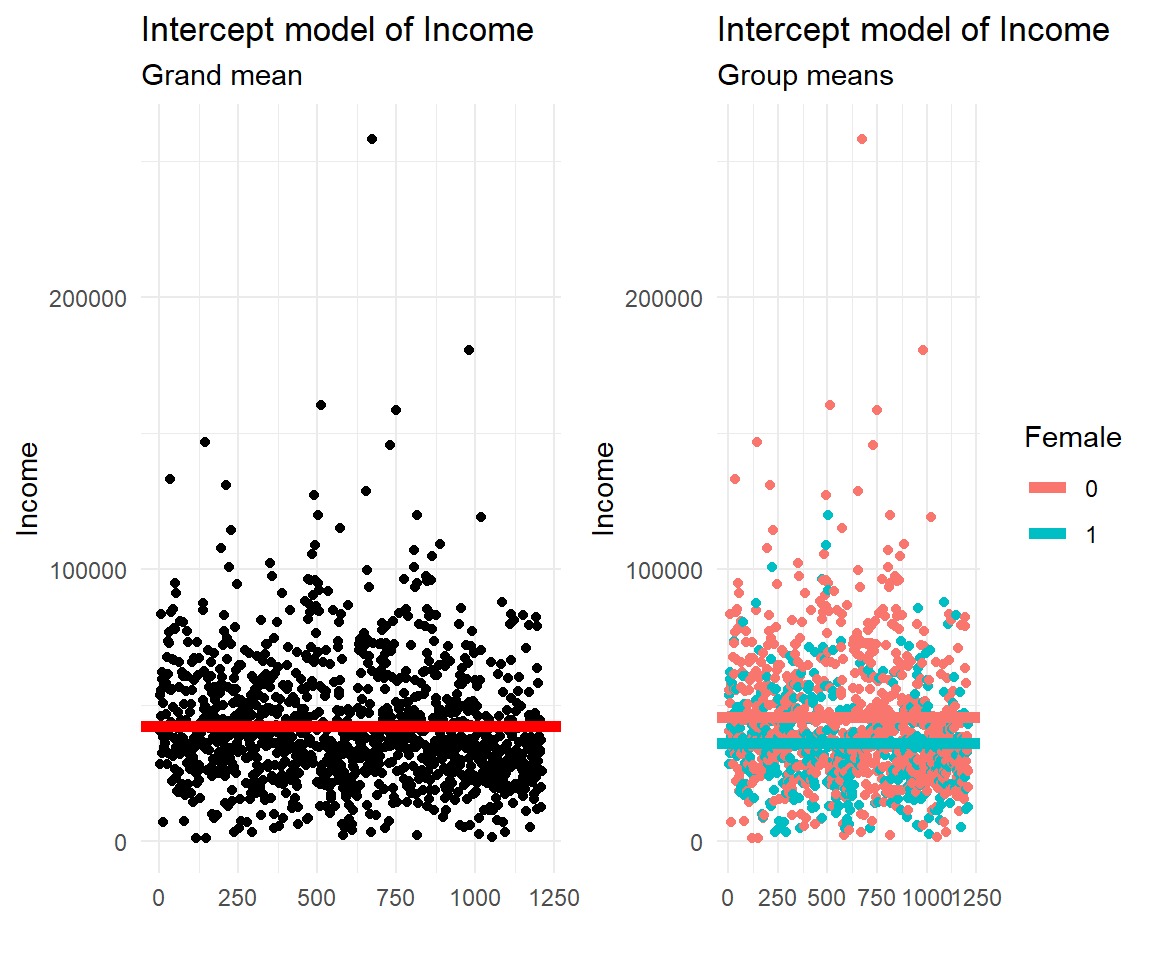
11.5 Simple Regression
Simple regression suggest a one-to-one relationship between two variables. In this section we focus on the continuous outcome variable income. We relate income to three different variables, age, gender and industry. Where age is another continuous variable, gender is a binary dummy and industry is a categorical variable.
11.5.1 X is continuous
Income and age are continuous in principle, i.e. they can be any real number in an interval. Actually, age is reported in natural numbers, full years due to measurement restrictions. In the real SOEP data, a more precise estimate of age can be derived as a date difference between date of birth and date of interview. Thus creating a measure with day units.
In practice, a scale from 0 to 10 is often treated as continuous. Although technically speaking a categorical or ordinal approach would match the nature of the measure better.
simple1 <- lm(Income ~ Age, data=soep)
modelsummary(title = 'Continuous Predictor.',
list("Income" = simple1),
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.',
coef_map = cm)| Income | |
|---|---|
| Age | 524.554 |
| (58.487) | |
| Constant | 18341.031 |
| (2733.469) | |
| Num.Obs. | 1211 |
11.5.2 X is a dummy
A dummy or binary variable describes two groups.
In the SOEP case the gender variable is named Female and coded 0 for male and 1 for female. In practice, it is likely to ease interpretation by renaming the variable to female, where 1 stands for having the feature and 0 for not having it. Dummies also come with different values like 1 and 2. Such a variable could be recoded to 0 and 1. Last but not least, note that SOEP and other studies still have a binary perspective on gender. We can imagine more gender groups, making it a categorical variable. There might be something like a continuous gender scale as well.15
simple2 <- lm(Income ~ Female, data=soep)
modelsummary(title = 'Dummy Predictor.',
list("Income" = simple2),
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.',
coef_map = cm)| Income | |
|---|---|
| Female | -9401.118 |
| (1383.445) | |
| Constant | 45498.875 |
| (826.288) | |
| Num.Obs. | 1211 |
11.5.3 X is categorical
We investigate annual income across different industries.
NACE is the acronym used to designate the various statistical classifications of economic activities developed since 1970 in the European Union (EU). NACE provides the framework for collecting and presenting a large range of statistical data according to economic activity in the fields of economic statistics (e.g. business statistics, labour market, national accounts) and in other statistical domains.
In level 2 of NACE there are 88 divisions identified by two-digit numerical codes (01 to 99). In the following we built a categorical variable industry from the level 2 NACE information in SOEP:
soep <- soep %>%
mutate(industry = case_when(NACE2 %in% c(1,2,3) ~ "Agriculture",
NACE2 %in% c(5:9) ~ "Mining",
NACE2 %in% c(10:32) ~ "Manufacturing",
NACE2 %in% c(35:38) ~ "Energy",
NACE2 %in% c(41:43) ~ "Construction",
NACE2 %in% c(50,51,52,55) ~ "Trade",
NACE2 %in% c(60,61,62,63,64) ~ "Transport",
NACE2 %in% c(65,66,67) ~ "Banking",
NACE2 %in% c(70,71,72,73,74,75,80,85,90,91,92,93,95,98,99) ~ "Services",
TRUE ~ "Other"))
table(soep$industry)
#>
#> Agriculture Banking Construction Energy Manufacturing
#> 14 9 80 26 299
#> Mining Other Services Trade Transport
#> 3 539 134 34 73simple3 <- lm(Income ~ industry, data=soep)
modelsummary(title = 'Categorical Predictor.',
list("Income" = simple3),
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.',
coef_map = cm)| Income | |
|---|---|
| Banking | 46123.264 |
| (9569.929) | |
| Construction | 8057.920 |
| (6489.108) | |
| Energy | 22774.586 |
| (7425.221) | |
| Manufacturing | 22032.617 |
| (6124.951) | |
| Mining | 31592.741 |
| (14250.493) | |
| Transport | 36264.336 |
| (6535.281) | |
| Trade | 11947.600 |
| (7112.908) | |
| Services | 25698.418 |
| (6291.360) | |
| Other | 14521.498 |
| (6063.652) | |
| Constant | 23434.559 |
| (5986.405) | |
| Num.Obs. | 1211 |
Note that with a categorical variable, one category is missing in the output by default (the so called base level). In this case it is Agriculture. All coefficients are in comparison with the average annual income in Agriculture. All coefficients are positive, indicating that all industries earn more than the Agriculture sector.
11.5.4 X is categorical, is it?
Actually, categorical variables are split into multiple dummy variable during the estimation process.
Truly Dedicated
We code the equivalence between linear regression with a categorical variable coded as a factor in R and a categorical variable split into multiple dummy variables.
# All variables are internally coded as "double"
glimpse(mtcars)
#> Rows: 32
#> Columns: 11
#> $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.2, 17.8,…
#> $ cyl <dbl> 6, 6, 4, 6, 8, 6, 8, 4, 4, 6, 6, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 8,…
#> $ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 140.8, 16…
#> $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, 180, 180…
#> $ drat <dbl> 3.90, 3.90, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.92, 3.92,…
#> $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3.150, 3.…
#> $ qsec <dbl> 16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20.00, 22.90, 18…
#> $ vs <dbl> 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,…
#> $ am <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0,…
#> $ gear <dbl> 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 3, 3,…
#> $ carb <dbl> 4, 4, 1, 1, 2, 1, 4, 2, 2, 4, 4, 3, 3, 3, 4, 4, 4, 1, 2, 1, 1, 2,…
# Cars have either 4, 6 or 8 cylinders
table(mtcars$cyl)
#>
#> 4 6 8
#> 11 7 14There are
# Factor coding: Use built in R style
mtcars <- mtcars %>%
mutate(cyl_fct = as_factor(cyl))
# Creating a dummy for each group
mtcars <- mtcars %>%
mutate(cyl4 = ifelse(cyl == 4, 1, 0),
cyl6 = ifelse(cyl == 6, 1, 0),
cyl8 = ifelse(cyl == 8, 1, 0))
# One hot encoding: every level of factor/categorical get its own column/dummy
# Dummy coding: there are k-1 dummies, because one is redundant The following types of regression are possible. First, treat cyl like a continuous variable. This might or might not make sense. R assumes, there are cars with all values of cylinders.
# Treated like continuous
model1 <- lm(mpg ~ cyl, data=mtcars)
# Treated like categorical (not showing base category)
model2 <- lm(mpg ~ cyl_fct, data=mtcars)
# One hot coding (all included, but one is NA)
model3 <- lm(mpg ~ cyl4 + cyl6 + cyl8, data=mtcars)
# Dummy coding (same coefficients, no NA)
model4 <- lm(mpg ~ cyl4 + cyl6, data=mtcars)
modelsummary(title = 'Categorical Predictor.',
list("MPG" = model1,
"MPG" = model2,
"MPG" = model3,
"MPG" = model4),
statistic = NULL,
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.|F')| MPG | MPG | MPG | MPG | |
|---|---|---|---|---|
| (Intercept) | 37.885 | 26.664 | 15.100 | 15.100 |
| cyl | -2.876 | |||
| cyl_fct6 | -6.921 | |||
| cyl_fct8 | -11.564 | |||
| cyl4 | 11.564 | 11.564 | ||
| cyl6 | 4.643 | 4.643 | ||
| Num.Obs. | 32 | 32 | 32 | 32 |
# Connection
# cylfct6 is -6.9 less than invisible base category
lm(mpg ~ cyl_fct, data=mtcars)
#>
#> Call:
#> lm(formula = mpg ~ cyl_fct, data = mtcars)
#>
#> Coefficients:
#> (Intercept) cyl_fct6 cyl_fct8
#> 26.664 -6.921 -11.564
# recalculate this as coefficient of cyl6 - cyl4
lm(mpg ~ cyl4 + cyl6, data=mtcars)$coefficients[3]-lm(mpg ~ cyl4 + cyl6, data=mtcars)$coefficients[2]
#> cyl6
#> -6.92077911.6 Parallel Slopes
Parallel Slopes is a special case of a multiple regression where there are multiple input variables that describe or explain an outcome. In particular, one of the variables is continuous (in this case age) and the other is a dummy variable (in this case gender). The resulting graph shows two parallel linear regression lines shifted by the dummy variable.
11.6.1 X is continuous + dummy
In contrast to the first Figure, we know consider all data at once and recognize gender as a factor influencing the annual income. The dummy variable gender offsets the age-income relationship.
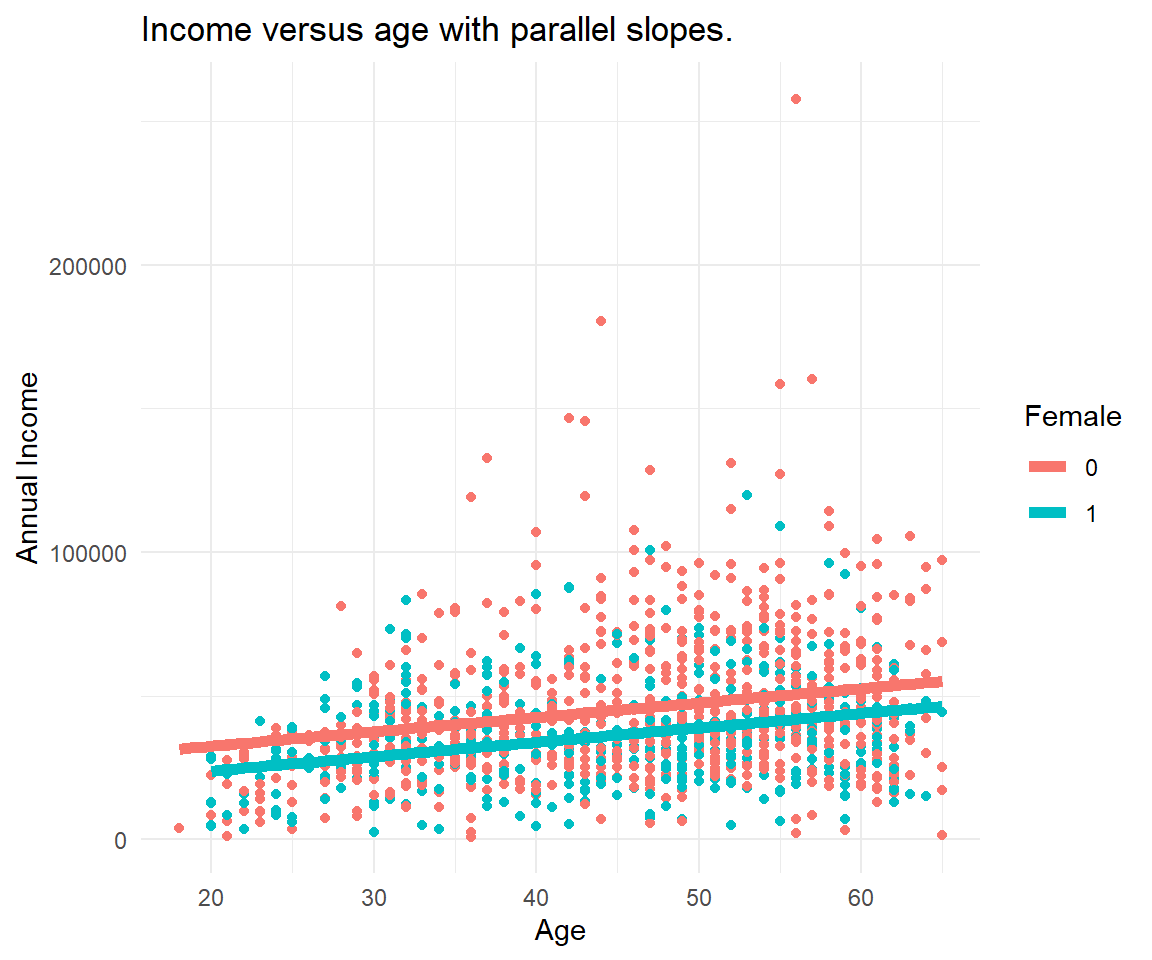
parallel1 <- lm(Income ~ Age + Female, data=soep)
modelsummary(title = 'Categorical Predictor.',
list("Income" = parallel1),
gof_omit = 'R2|AIC|BIC|RMSE|Log.Lik.',
coef_map = cm)| Income | |
|---|---|
| Age | 501.348 |
| (57.643) | |
| Female | -8670.282 |
| (1345.244) | |
| Constant | 22487.063 |
| (2764.643) | |
| Num.Obs. | 1211 |
11.7 Model Comparison
multiple <- lm(Income ~ Age + Female + industry, data=soep)
modelsummary(title = 'Linear regression models compared.',
list("Income" = simplest,
"Income" = simple1,
"Income" = simple2,
"Income" = simple3,
"Income" = parallel1,
"Income" = multiple),
gof_omit = 'RMSE|Log.Lik.|F|AIC|BIC',
metrics = "all",
coef_map = cm)| Income | Income | Income | Income | Income | Income | |
|---|---|---|---|---|---|---|
| Age | 524.554 | 501.348 | 478.369 | |||
| (58.487) | (57.643) | (54.886) | ||||
| Female | -9401.118 | -8670.282 | -9164.068 | |||
| (1383.445) | (1345.244) | (1323.594) | ||||
| Banking | 46123.264 | 46653.149 | ||||
| (9569.929) | (9090.316) | |||||
| Construction | 8057.920 | 8349.413 | ||||
| (6489.108) | (6164.261) | |||||
| Energy | 22774.586 | 23587.586 | ||||
| (7425.221) | (7053.065) | |||||
| Manufacturing | 22032.617 | 23113.979 | ||||
| (6124.951) | (5819.116) | |||||
| Mining | 31592.741 | 31652.597 | ||||
| (14250.493) | (13539.296) | |||||
| Transport | 36264.336 | 37942.568 | ||||
| (6535.281) | (6210.851) | |||||
| Trade | 11947.600 | 14909.762 | ||||
| (7112.908) | (6761.498) | |||||
| Services | 25698.418 | 28857.012 | ||||
| (6291.360) | (5993.555) | |||||
| Other | 14521.498 | 17854.146 | ||||
| (6063.652) | (5773.785) | |||||
| Constant | 42145.215 | 18341.031 | 45498.875 | 23434.559 | 22487.063 | 2670.410 |
| (674.976) | (2733.469) | (826.288) | (5986.405) | (2764.643) | (6232.343) | |
| Num.Obs. | 1211 | 1211 | 1211 | 1211 | 1211 | 1211 |
| R2 | 0.000 | 0.062 | 0.037 | 0.097 | 0.094 | 0.187 |
| R2 Adj. | 0.000 | 0.062 | 0.036 | 0.091 | 0.092 | 0.180 |
Definition
R square (R2) is a statistical measure that represents the proportion of the variance in the dependent variable that is explained by the independent variable(s) in a regression model. It is also known as the coefficient of determination.
R2 measures how well the regression model fits the data. R2 can range from 0 to 1, where 0 indicates that none of the variance in the dependent variable is explained by the independent variable(s), and 1 indicates that all of the variance in the dependent variable is explained by the independent variable(s). A higher R2 indicates a better fit between the model and the data, meaning that more of the variability in the dependent variable can be explained by the independent variable(s) in the model. The formula for R2 is:
\[R2 = 1 - \frac{SSR}{SST} = 1 - \frac{\text{sum of squares residuals}}{\text{total sum of squares}} = 1 - \frac{\displaystyle\sum \left(\hat{y}- \overline{y}\right)^2}{\displaystyle\sum \left(y - \overline{y}\right)^2} \]
A good R2 – In some fields like social sciences or economics, an R2 value of 0.3 or higher may be considered a good fit for a model. In other fields like physics or engineering, a higher R2 value of 0.7 or above may be necessary to demonstrate a good fit.
R2 inflation – R2 usually increases with sample size. In least squares regression using typical data, R2 is at least weakly increasing with increases in the number of regressors in the model. Because increases in the number of regressors increase the value of R2, R2 alone cannot be used as a meaningful comparison of models with very different numbers of independent variables.
Definition
Adjusted R2 is a modified version of R2 that takes into account the number of independent variables in a regression model.
\[\text{Adjusted R2} = 1 - \left[ (1 - R2) \cdot \frac{n - 1}{n - k} \right] \tag{with intercept}\] \[\text{Adjusted R2} = 1 - \left[ (1 - R2) \cdot \frac{n - 1}{n - k - 1} \right] \tag{no intercept}\]
11.8 Transform to Perform
While a lot of statistics and econometrics deals with linear relationships, we live in a very non-linear world. By taking the logarithm of your data, you can reduce the range of values and make it easier to see patterns and relationships. Log transformation is a common technique to deal with skewed or highly variable data, such as income. Income data often have a long right tail, meaning there are few individuals with very high incomes, but many with lower incomes (left panel). When modeling income in a regression, this can cause issues because the distribution violates the normality assumption that underpins many regression techniques.
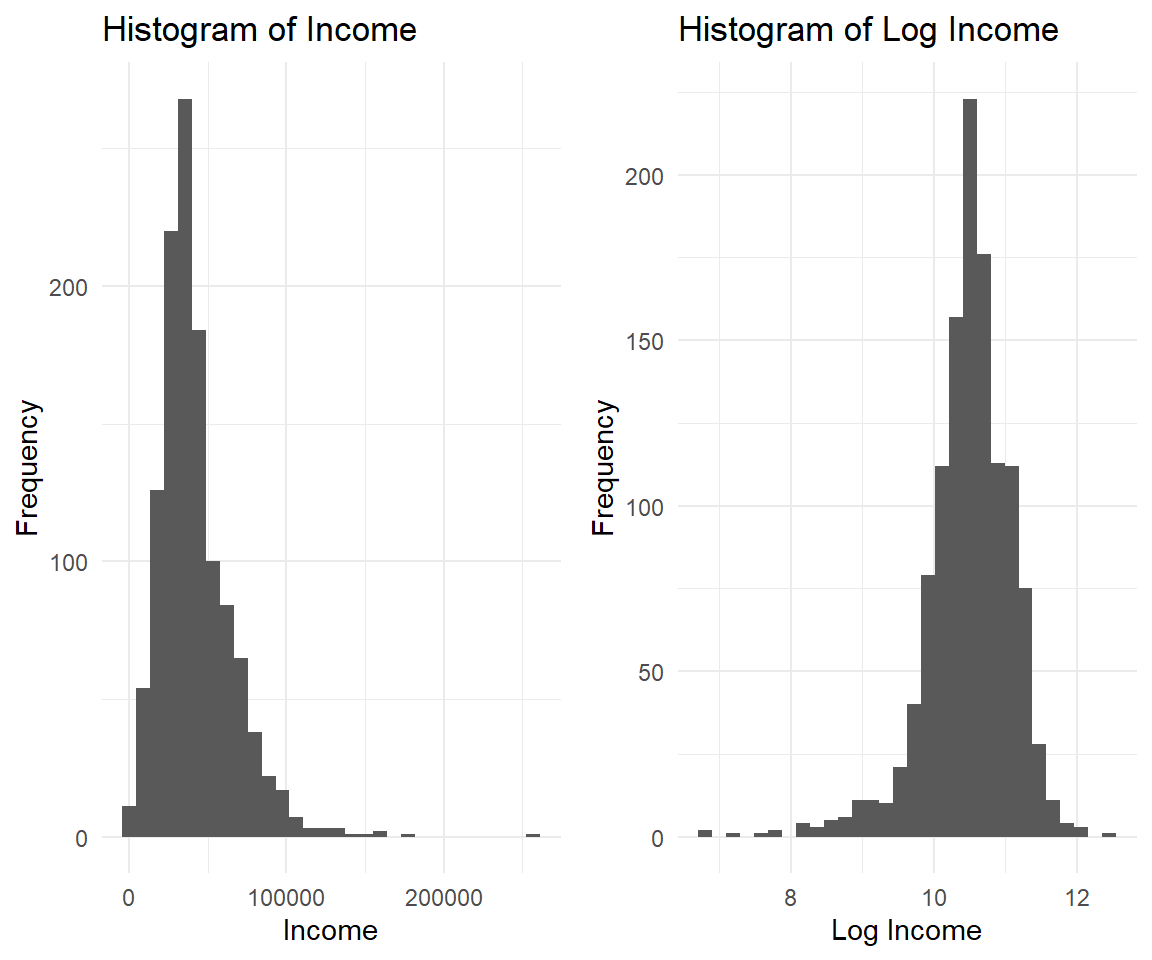
Remember some key points of log:
- The log can only be calculated for numbers > 0.
- The log of values between 0 and 1 is negative.
- The log of values above 1 is positive.
- The log of 1 is 0.
How to do logs in R?
# Logs in R
x <- c(0.1,0.5,1,2,5)
x_log <- log(x)
data.frame(x, x_log)
#> x x_log
#> 1 0.1 -2.3025851
#> 2 0.5 -0.6931472
#> 3 1.0 0.0000000
#> 4 2.0 0.6931472
#> 5 5.0 1.6094379It's natural.
The default of log() is the natural logarithm. There are other logs as well, e.g. with base 10 log(x, base = exp(10)).
The above specification of income versus age as two non-transformed variables is also known as a linear-linear model or level-level model. You can have a log transformation on the left, the right or both sides. All log-transformations change the interpretation of the regression coefficient. We explore these options in the following.
The log-linear or log-level model.
log_linear <- lm(log(Income) ~ Age + Female + industry, data=soep)
log_log <- lm(log(Income) ~ log(Age) + Female + industry, data=soep)
linear_log <- lm(Income ~ log(Age) + Female + industry, data=soep)| Income | Log (Income) | Log (Income) | Income | |
|---|---|---|---|---|
| Age | 478.369 | 0.014 | ||
| (54.886) | (0.001) | |||
| Log (Age) | 0.624 | 20595.612 | ||
| (0.058) | (2226.835) | |||
| Num.Obs. | 1211 | 1211 | 1211 | 1211 |
| R2 | 0.187 | 0.177 | 0.189 | 0.193 |
| R2 Adj. | 0.180 | 0.169 | 0.182 | 0.186 |
Regression coefficients interpretation.
Here are the interpretations:
- Linear-Linear: For each additional year of age, we expect 478 € more annual income on average. Easy peasy.
- Log-Linear (semi-elasticity): For each additional year of age, we expect annual income to increase by \((e^{0.014} - 1) * 100 = 1.4\) % on average. Starting from the average annual income of 42145 € one more year in age increases income by 590 €.
- Log-Log (elasticity): For each additional 1% increase in age, we expect the annual income to increase by 0.62 % €. For a 30-year-old earning average annual income, a 1% increase in age means 0.3 years or 3.6 months, increasing annual income by 261 €.
- Linear-Log: For each additional 1% increase in age, we expect the annual income to increase by 206 € For a 30-year-old, additional 1% or 3.6 month are expected to increase annual income by 206 €.
Of course other mathematical transformations are possible and some are common, for example the square root or polynomial transformation (the power of two or three). Stutzer and Frey (2008) study the effect of commuting time (and commuting time squared) on life satisfaction (Tables 1 to 4).
The same consideration is so handedness. Normally, people are classified a left-hander or right-hander. But you can make a case for ambidextrous people using both hands equally good as well as a mixture of hand usage, making handedness a continuous concept.↩︎